
Atlassian’s Jira and Confluence are powerful tools for collaboration, project management, and team alignment. However, when it comes to preserving and collecting data for legal or compliance purposes, they introduce unique challenges.
These platforms were designed for flexibility and productivity, not the rigorous demands of eDiscovery. Legal and compliance teams often face a daunting task: how do you defensibly preserve and collect the highly customized, intricate, constantly evolving data stored in these tools?
Let’s explore what makes Jira and Confluence so complex for eDiscovery and the strategies organizations can use to manage these challenges effectively.
Jira and Confluence were built for collaboration, but their features create obstacles for defensible data preservation. In Jira, workflows, comments, attachments, and metadata provide essential context for tasks. Similarly, Confluence pages are rich with collaborative edits, inline comments, and version histories. Capturing one element in isolation strips away this context, reducing the defensibility and utility of the data for legal purposes.
Adding to the challenge is the dynamic nature of these platforms. Data evolves constantly—comments are added, workflows adjusted, and edits made in real time. Static snapshots are inadequate for capturing this fluidity, and organizations need solutions that can adapt to these ongoing changes.
APIs, while a vital tool for accessing data, in many ways weren’t designed for eDiscovery. They often lack access to critical components like metadata, comment threads, and historical changes. Organizations that rely solely on APIs—or wait for purpose-built eDiscovery APIs—risk leaving significant gaps in their data collection processes, especially as enterprise SaaS adoption accelerates.
The case for preserving data in native contexts
Courts have increasingly emphasized the importance of preserving dynamic data in its original context. For instance, in a Salesforce case (Famulare v. Gannett Co.), the court ruled that content must be produced as screenshots, if possible, or explained through deposition, as this reflected how the data was stored and accessed in the ordinary course of business. This precedent highlights the importance of presenting data as it appears in its native format, strengthening the case for solutions like Hanzo Illuminate, which ensure data is preserved in its full, defensible context.
While APIs play an important role in data collection, they have inherent limitations when applied to legal-grade preservation. They may provide access to basic data, such as task titles or summaries, but they often fail to capture deeper layers of information, like version histories or the relationships between attachments and metadata. Additionally, API’s alone may not present vital information in a format or style now preferred by US Courts.
Without these components, legal teams face incomplete records that could undermine compliance or litigation efforts. To address these gaps, organizations need solutions that go beyond API capabilities.
A hybrid approach that combines API access with advanced technologies offers a way to bridge these limitations. By augmenting APIs with tailored tools, organizations can collect data comprehensively and in its full context, ensuring defensibility and future-proofing their processes.
Effectively managing Jira and Confluence data requires more than surface-level solutions. These platforms are dynamic, and their complexity demands tailored approaches to ensure complete, defensible data preservation.
Dynamic preservation is critical. Solutions must actively track changes in real time—capturing edits, newly added comments, and updates to workflows. It’s equally important to preserve the relationships between elements, such as metadata, attachments, and comments, to maintain the context that makes the data actionable and defensible.
By focusing on completeness and context, organizations can create data records that align with the rigorous demands of legal and compliance standards.
Over years of working with platforms like Jira and Confluence, several key insights have emerged. APIs are a valuable starting point for data collection, but they’re rarely sufficient on their own. Augmenting APIs with technologies like Hanzo Illuminate ensures that organizations stay ahead of rapidly evolving data challenges.
Flexibility is essential. Every organization uses Jira and Confluence differently, with custom workflows and configurations. Solutions must adapt to these unique structures while maintaining defensibility.
Finally, a combination of advanced technology and expertise is crucial. Tools like Hanzo Illuminate provide a robust technical foundation, but it takes knowledgeable teams to tailor these solutions to the specific needs of legal and compliance workflows.
Hanzo Illuminate was purpose-built to address the unique challenges of preserving and collecting data from dynamic collaboration tools like Jira and Confluence. By combining advanced integrations, proprietary technology, and deep expertise, Hanzo goes beyond traditional methods to provide a comprehensive, defensible solution.
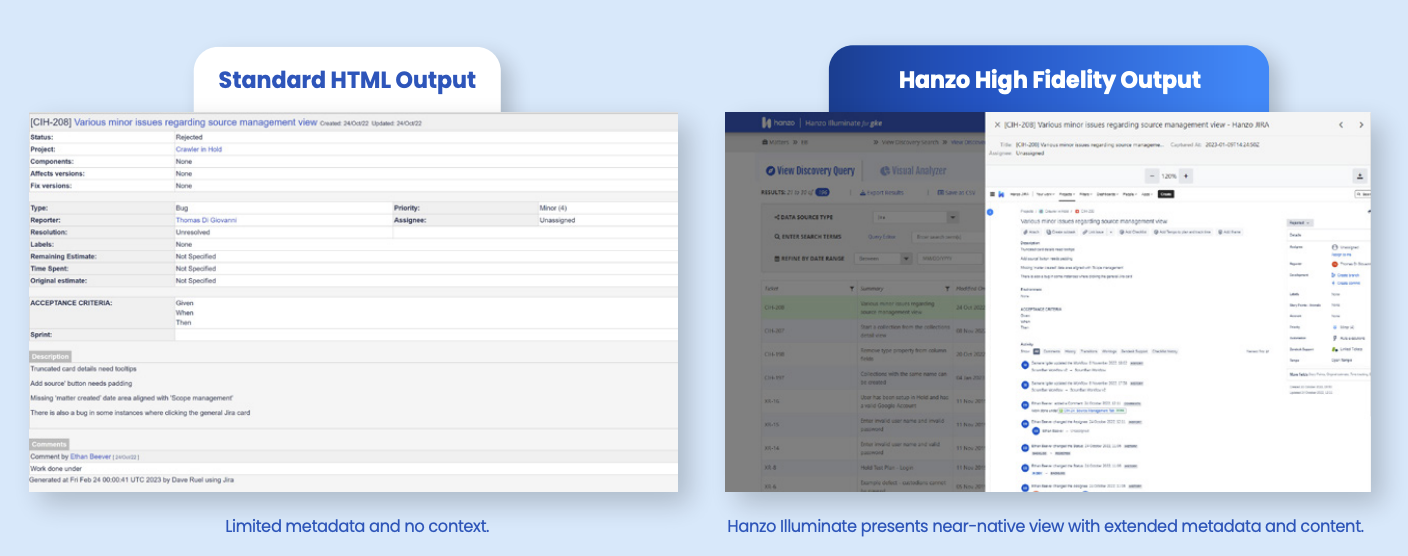
The complexity of preserving and collecting data from Jira and Confluence is only growing as organizations become more reliant on these tools. Combining APIs with cutting-edge Dynamic Capture Technology creates a future-proof strategy that ensures completeness, context, and defensibility.
As organizations continue to rely on Atlassian tools for collaboration, the importance of robust, adaptable data preservation will only grow. With Hanzo Illuminate, legal and compliance teams can navigate these challenges confidently, ensuring they meet the highest standards of eDiscovery and compliance.
If your organization is grappling with the complexities of preserving and collecting data from Jira and Confluence, get in touch with Hanzo experts to see how Hanzo solutions can transform your process.
 Hanzo Team
Hanzo Team 


{kind=link}